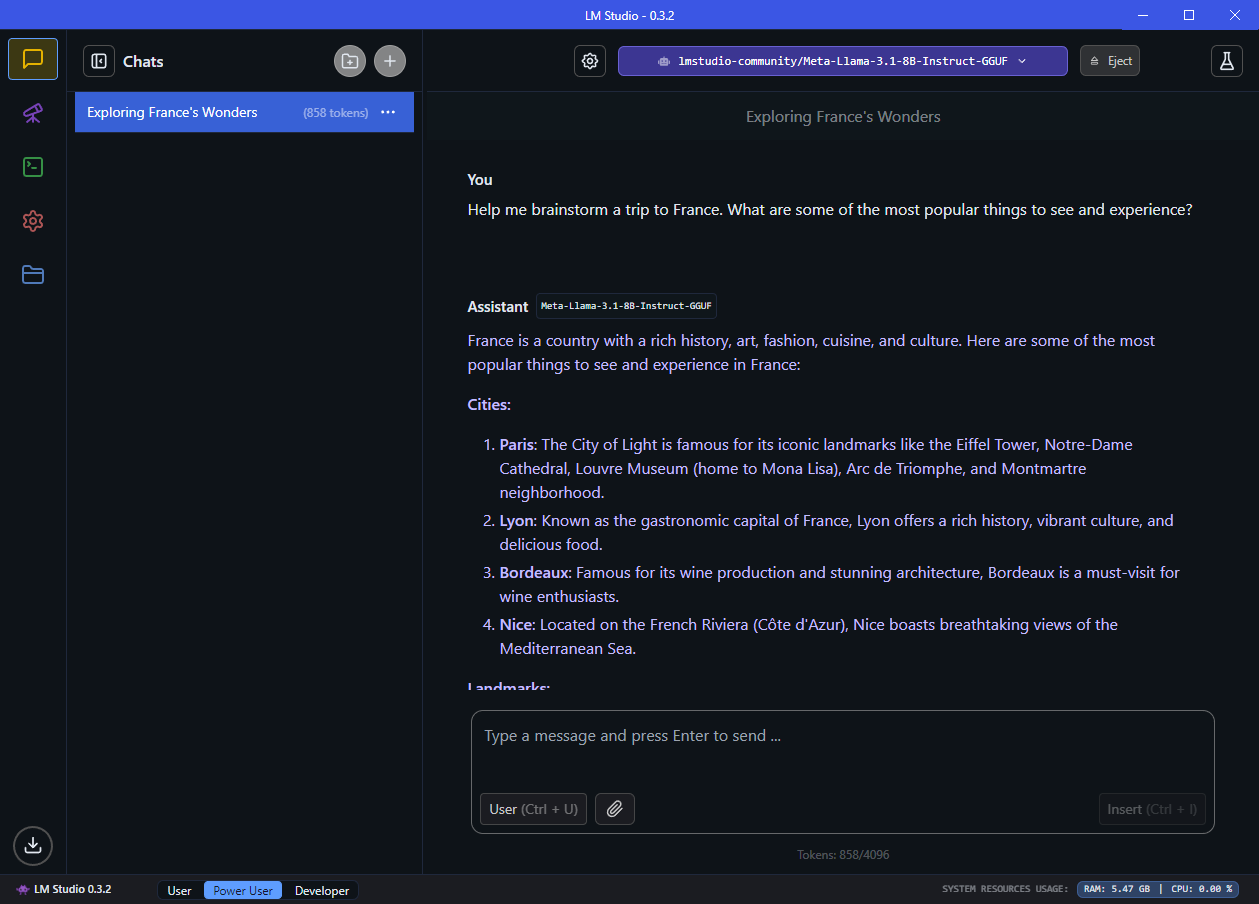
When I first started tinkering with large language models (LLMs) last summer, I began where most did, experimenting with ChatGPT and other publicly available foundational models. As I dug deeper, I even took a refresher course in Python, and learned how to write code to utilize the OpenAI APIs. To say the least, I pretty-much dove in head first.
However, I realize that not everyone has that kind of time to spend learning, and most techies want just a simple way to experiment with new things. So, with that in mind, my first post is going to introduce a simple way for people to start having fun with LLMs running locally. I have found that while the foundational models can give the most robust answers, they can require premium subscriptions; whereas a locally running LLM gives decent answers and doesn’t require a credit card.
One of the first programs I found when I was learning was LM Studio (lmstudio.ai). The software has an easy to use interface, and comes with a quick Windows, Mac, or Linux installer allowing you to download open-source models to tinker with right away. For this article, I will help guide you through using LM Studio for the first time, as well as explain some of the key concepts and nomenclature for using LLMs.
Getting started
Once you download LM Studio and get it installed, the first screen prompts you to choose a path to store the models. I created a new folder on my D: drive because some of the models are large, and if you start collecting them, they tend to take up a lot of space.
Once the download location is specified, you can now go browsing for models by clicking on the purple telescope icon in the left-hand column. If you cannot see the purple telescope, ensure you select the Power User mode from the bottom.
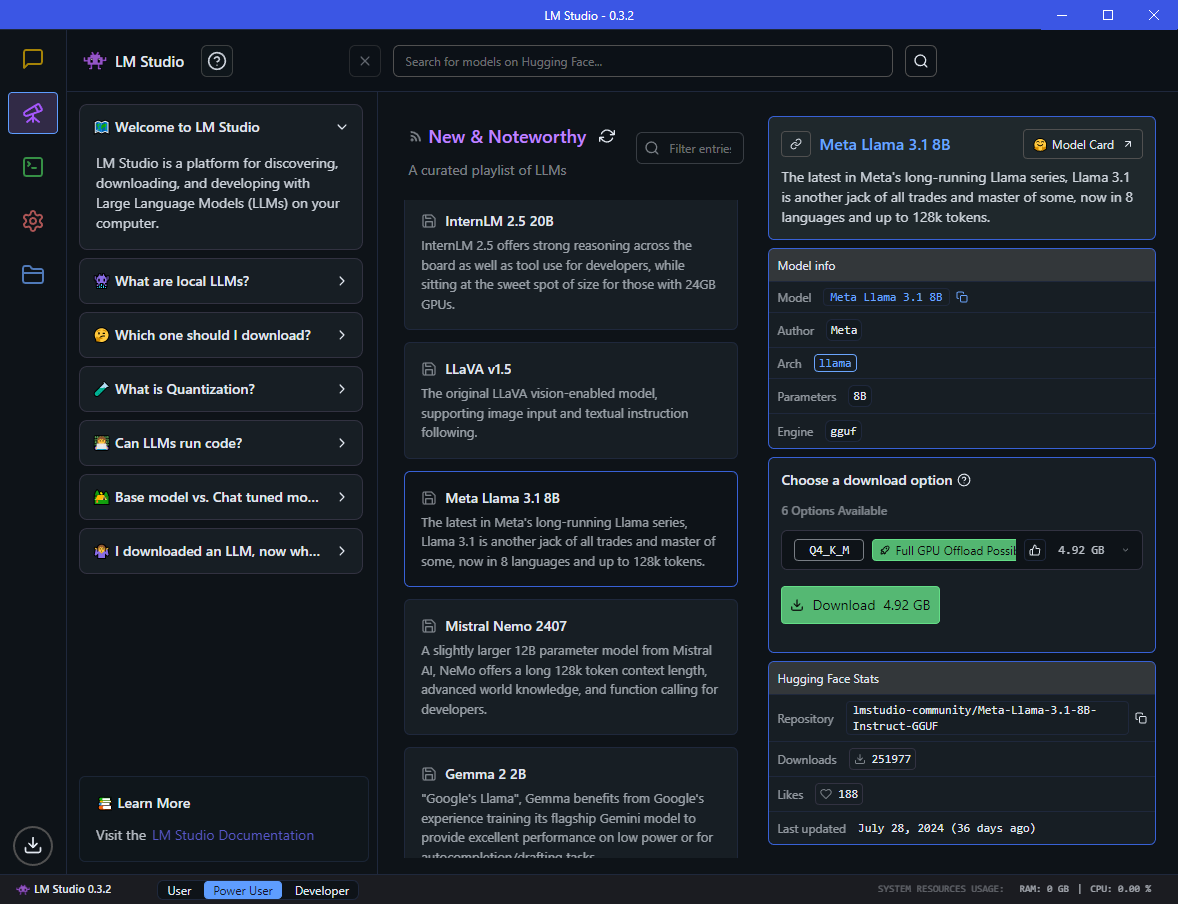
The left pane has a bunch of beginner’s tips explaining LLMs, how to pick models, quantization, etc., which I highly recommend you take a minute to read through their quick FAQs to learn more.
Which model should I download?
This is not that easy of a question to answer, because it all depends on what you want to do with it. If you are just getting started, LM Studio recommends you start with a model from the New & Noteworthy section (see above). The “Meta Llama 3.1 8b” as shown in the screenshot is pretty popular amongst enthusiasts, and a good place to start for a general purpose LLM.
However, before you click on the download button, let me explain some of the basics and nomenclature of the models.
First, let’s break down the name: “Meta Llama 3.1 8b”.
- Meta – Yes, the company that owns Facebook, created this model and released it.
- Llama – What they named this model.
- 3.1 – The released version of the model.
- 8b – The number of parameters in this model. 8b means 8 billion. Think of parameters as the total number of training data items baked into the model. The larger the number of parameters, the more data the model has learned from, and thus the more robust the answers it can respond with to your queries.
In the model description, it says that it can understand eight languages and cites “up to 128k tokens”. This is telling us that the “context window is 128,000 tokens”. While it is not super important to understand context windows and tokens at this point in our conversation, it is overall helpful in understanding LLMs in general. You see, when you communicate with an LLM, it doesn’t actually understand English words. It breaks down a sentence into smaller pieces called tokens (with bigger words being broken into multiple tokens), typically about 4 characters per token. These tokens are then converted into embeddings, which are large floating-point numbers that the computer can understand. In laymen’s terms, 100 tokens is typically around 75 words. That said, the context window is the maximum number of tokens you can feed into it for your query. So, in this example, if you have multiple pages of text that you want it to summarize, a 128k context window means that you can only feed in about 96,000 words.
Back to the model info. While it is not shown on this screen, interestingly, the Llama 3.1 model has three different parameter sizes you can choose from. 405b parameters (which is up to 431 GB), 70b parameters (which is up to 75 GB), and 8b which is typically between 3.2-16 GB depending on which version you download.
Naturally, you are thinking, I want the smartest model, why wouldn’t I choose the largest one? In most cases, the answer is speed. You see, for the model to spit out answers faster than one word per second, it is best stored fully in VRAM. For example, my computer has 32 GB of system RAM and my NVIDIA GeForce RTX 4080 has 16 GB of VRAM. Ideally, I need the model to be small enough to fit into one or the other, but ideally into my 16 GB of VRAM for full GPU offload.
That is where quantization comes into the picture. Quantization is a mathematical method used to reduce the model’s parameters from 64, 32, or 16-bit floating point numbers down into 8-bit or 4-bit precision to save space. Think of it as compressing a model just like zipping a file, which allows the model to fit into the VRAM/RAM commonly found in consumer-grade hardware. (As a side note, the resulting quantized model that LM Studio uses is stored in a popular file format called GGUF. The GPT-Generated Unified Format, and is a special binary file type for storing a wide range of models.)
Of course, using a smaller quantized model does have its tradeoffs with regards to precision. Too small and its efficacy starts to degrade, so some testing of different sized “quants” may be required to find the level that best meets your needs.
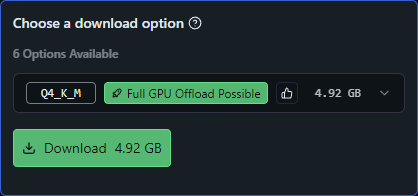
As you can see, LM Studio is recommending the Q4_K_M quantization that will consume 4.92 GB, and it is letting me know that “Full GPU Offload is possible”, for the best speed and performance.
Back to nomenclature, Q4 means that this is a 4-bit quant, whereas “K_M” indicates the quantization method used “K-Means” clustering, and the “M” represents the model size as medium (S=Small, M=Medium, L=Large). The math behind these methods is way beyond the scope of this article, but just know that as you are browsing quants, you will find that the _K_M types are very popular because it typically is a good balance between size while retaining a lot of the initial “smarts”. If you want to learn more, here is an article that explains Quantization of LLMs with llama.cpp by Ingrid Stevens.
In addition, LM Studio will let you know how many different options (or quants) are available for download. If you click the carrot next to a particular model size, you can see the various other quants available. This is an example of the “InternLM 2.5 20B” model to illustrate the offload status icons.
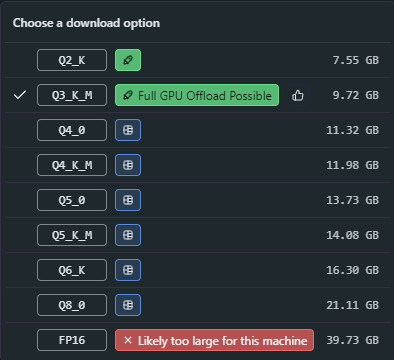
LM Studio is helpful in the fact that it will let you know the offload status before you download it. Full offload is best (VRAM/GPU preferred), whereas partial would have to spill part of the model into regular system RAM, which is much slower. “Likely too large for this machine” means you simply don’t have enough system resources to use that size model, so don’t bother downloading it.
Once you choose the option it recommends, a few minutes later the model’s GGUF file is downloaded and is ready to go.
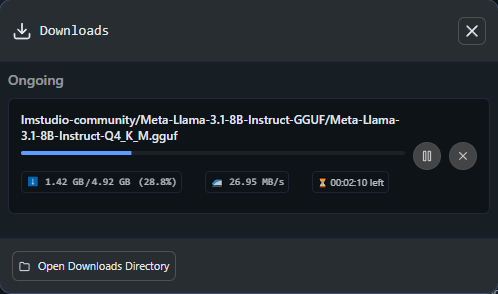
At this point, you can click on the button to “Load Model”. This is just telling LM Studio which model you want it to use. With the model now loaded you can start having a conversation and ask it questions.
Nomenclature side note: This process of the model using what it has previously learned to answer your question is called inference.
The final thing that I want to point out is the “new chats” (the + button). Much like having a conversation with another human, when you change subjects, it is good to start a new chat. That way, it knows what topic you are discussing just in case you add any follow up questions.
Conclusion
LM Studio is one of my favorite tools that I commonly recommend to friends to get started, so I really hope that this mini-tutorial will help to enhance your productivity by harnessing the power of LLMs running locally.
Next up: Building your AI playground (Part 1) – Getting WSL running on Windows