
Earlier this week, I stumbled upon a Reddit post discussing the performance differences between Ollama running natively in Windows versus it running within Linux on WSL2, so I thought that I would test it out.
Disclaimer: While I wouldn’t consider my testing to be 100% scientific, I tried my best to get the best results possible.
Here is how I set up the test:
- I used the latest version of Ollama on both operating systems – version 0.3.14
- I downloaded the same model to both – llama3.2:latest, Parameters: 3.21b, Quantization: Q4_K_M
- For my GPU I am using an NVIDIA GeForce RTX 4080 with 16 GB GDDR6X
- I used the basic Ollama prompt instead of a web front end like Open WebUI
For the Windows portion of the testing, I started by installing Ollama for Windows.
And since my Linux instance was still running at the time, I had to set the default Ollama API port to something different using an environment variable, and then started the server.
C:\Users\dschmitz>set OLLAMA_HOST=127.0.0.1:11435
C:\Users\dschmitz>ollama serve
2024/11/02 08:44:37 routes.go:1158: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11435 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:C:\\Users\\dschmitz\\.ollama\\models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-11-02T08:44:37.726-05:00 level=INFO source=images.go:754 msg="total blobs: 0"
time=2024-11-02T08:44:37.726-05:00 level=INFO source=images.go:761 msg="total unused blobs removed: 0"
time=2024-11-02T08:44:37.726-05:00 level=INFO source=routes.go:1205 msg="Listening on 127.0.0.1:11435 (version 0.3.14)"
time=2024-11-02T08:44:37.727-05:00 level=INFO source=common.go:49 msg="Dynamic LLM libraries" runners="[cpu cpu_avx cpu_avx2 cuda_v11 cuda_v12 rocm_v6.1]"
time=2024-11-02T08:44:37.727-05:00 level=INFO source=gpu.go:221 msg="looking for compatible GPUs"
time=2024-11-02T08:44:37.727-05:00 level=INFO source=gpu_windows.go:167 msg=packages count=1
time=2024-11-02T08:44:37.727-05:00 level=INFO source=gpu_windows.go:214 msg="" package=0 cores=10 efficiency=0 threads=20
time=2024-11-02T08:44:37.939-05:00 level=INFO source=types.go:123 msg="inference compute" id=GPU-7494b07a-24c6-9c1e-a630-54a4e412eed2 library=cuda variant=v12 compute=8.9 driver=12.6 name="NVIDIA GeForce RTX 4080" total="16.0 GiB" available="14.7 GiB"Once the Windows Ollama server was running, I opened a second command prompt, and started my testing using the Ollama prompt.
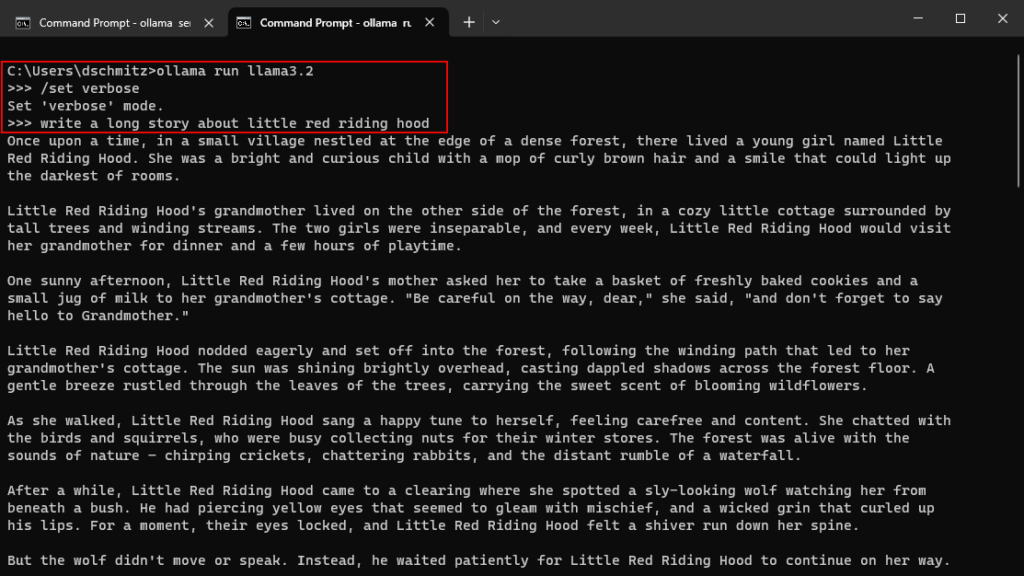
As you can see from the screenshot, I set the it to verbose mode, so that it outputs the statistics at the bottom of each result like this:
C:\Users\dschmitz>ollama run llama3.2
>>> /set verbose
Set 'verbose' mode.
>>> write a long story about little red riding hood
Once upon a time, in a small village nestled at the edge of a dense forest, there lived a young girl named Little
Red Riding Hood.
...
...
total duration: 7.2977744s
load duration: 17.5168ms
prompt eval count: 34 token(s)
prompt eval duration: 284.146ms
prompt eval rate: 119.66 tokens/s
eval count: 1005 token(s)
eval duration: 6.99479s
eval rate: 143.68 tokens/s
>>> Send a message (/? for help)I ran the same prompts multiple times on both Windows and Linux running within WSL, and here were the results of the first round.
| Prompt | Win-Tokens | Win-Tokens/s | Linux-Tokens | Linux-Tokens/s | Tok/s Difference |
| write a long story about little red riding hood | 1005 | 143.68 | 1114 | 124.37 | 15.52% |
| write a really long extended story about little red riding hood with lots of imagery and details | 1945 | 133.75 | 1931 | 125.09 | 6.92% |
| write a game in python to play guess a number | 549 | 133.97 | 401 | 126.76 | 5.68% |
| In Ubuntu Linux, what does the grep command do? | 569 | 137.61 | 477 | 121.24 | 13.50% |
| Averages | 1017 | 137.25 | 980.75 | 124.37 | 10.41% |
Just to make sure that there wasn’t any interference from both Ollama instances running at the same time, for the second round I stopped the Linux version while Windows was running, and vice versa.
| Prompt | Win-Tokens | Win-Tokens/s | Linux-Tokens | Linux-Tokens/s | Tok/s Difference |
| write a long story about little red riding hood | 1516 | 143.40 | 1138 | 127.11 | 12.81% |
| write a really long extended story about little red riding hood with lots of imagery and details | 1676 | 145.74 | 1921 | 122.45 | 19.02% |
| write a game in python to play guess a number | 273 | 144.79 | 277 | 128.28 | 12.87% |
| In Ubuntu Linux, what does the grep command do? | 432 | 138.09 | 476 | 127.73 | 8.11% |
| Averages | 974.25 | 143.005 | 953 | 126.3925 | 13.20% |
Conclusion
Going into this test, I was fully expecting the WSL instance to have some degree of overhead due to the WSL2 virtualization. However, based on the comments on Reddit, I didn’t know what to expect. In my opinion, I don’t think that a 10-13% difference in tokens per second makes that much of a difference. On the other hand, if you want to squeeze every last drop of performance out of your GPU, then running Ollama native on Windows, seems to be the way to go.